CNN-based GAN이 아닌 ViT를 GAN에 처음 적용한 논문이라 흥미로워서 읽어보았다. 또한, ViT를 GAN에 적용하며 생긴 불안정성을 해결하는 방법들도 알 수 있었다.
1. Introduction
CNN은 Conv의 weight-sharing, local-connectivity, Pooling의 translation equivariance(input value의 위치가 변함에 따라 output value도 변한다) 성질이 있어 powerful한 capability를 갖는 덕분에 현재까지 Computer Vision 분야에서 주로 사용되고 있다.
최근에는 Transformer 구조도 image and video recongnition task에서 좋은 성능을 보이며 CNN과 견주고 있다.
그 중 ViT는 image를 token들의 sequence로 해석하는데, ImageNet benchmark에서 더 적은 computational budget(더 적은 FLOPs)으로도 비슷한 classification 성능을 달성했다.
또한, CNN의 local-connectivity와 다르게 ViT는 globally-contextualized representation(each patch is attended to all patches)을 다룬다. ViT는 non-local contextual dependencies를 모델링하는 데 이점이 있고 효율성과 확장성을 보여주고 있다. 최근에는 object detection, video recognition, multitask pretraining 등 다양한 작업에 사용되고 있다.
이 논문에서는 이러한 ViT를 image generation 분야에도 적용하고 convolution이나 pooling을 사용하지 않고도 CNN-based GAN과 견줄만한 성능을 내고자 한다. 하지만, ViT-based GAN은 더욱 불안정하고, 기존의 regularization 방법(gradient penalty, spectral normalization)으로는 ViTGAN의 불안정성을 해결할 수 없었다.
따라서 이 논문에서는 ViTGAN 학습을 안정화하고 잘 수렴할 수 있도록 기존 방법들을 변형해 새로운 방법들을 제시한다.
Discriminator → self-attention에서의 enforcing lipschitzness, improved spectral normalization
Generator → architecture 설계, layer normalization과 output mapping layers의 변형 (수정된 ViT Generator는 ViT-based, CNN-based Discriminator 둘 다에서 적대적 훈련을 더 용이하게 하는 결과를 보여줬다)
앞서 연구된 Transformer-based GAN model인 TransGAN의 성능을 뛰어넘고 CNN-based GAN model인 StyleGAN2와도 비슷한 성능을 달성했다. ViT를 GAN에 적용한 첫 논문이고 GAN에서 Transformer로도 CNN에 견줄만한 성능을 낸 첫 논문이다.
2. Related work
계속 다뤄왔던 내용이기에 간단하게만 정리한다.
GAN
GAN의 불안정한 학습을 해결하기 위해 다양한 방법들이 제시됐지만, 다 CNN-based GAN에서의 해결 방법들로 Transformer-based GAN에는 적용될 수 없었다.
Vision Transformer
ViT는 대규모 데이터 셋에 대한 pre-training을 활용하여 기존 CNN에 비해 Transformer architecture의 우수성을 보여준다.
그 후, DeiT는 regularization trick 뿐 아니라 knowledge distillation을 통해 ImageNet dataset 만으로 ViT정도의 성능을 냈다. MLP-Mixer는 self-attention을 MLP로 대체하여 per-location feature를 mixing한다.
이렇게 다양한 분야에 확장되고 있는 ViT를 GAN에 적용하려고 한다.
Generative Transformer in Vision
Transformer by autoregressive learning, cross-modal learning between image and text등의 연구들은 image generation을 autoregressive sequence learning problem으로 모델링한 방법들이다.
반면, 우리는 Vision Transformer를 generative adversarial training 패러다임에서 학습시킨다. 비슷한 연구로 TransGAN이 있는데 여기서는 학습 안정성에 대한 기술을 다루지 않고, CNN-based GAN 방법에 비해 성능이 상당히 떨어진다. 우리 논문에서 Transformer-based GAN이 CNN-based GAN과 비교해 경쟁력 있는 성능을 달성할 수 있음을 처음으로 보여준다.
3. Preliminaries: Vision Transformers (ViTs)

이미지를 patch 단위로 자르고, 학습 가능한 classification embedding xclass를 포함하고, positional embedding Epos를 더해 patch embedding h0를 만든다. 이를 Transformer Encoder에 여러번 통과시키는데, MSA(multi-headed self-attention), MLP를 거치고 각각의 이전에 LN(layer normalization)을 수행한다.
4. Method
4.1. Regularizing Vit-based discriminator
Enforcing Lipschitzness of Transformer Discriminator
립시츠 연속성은 GAN discriminator에서 중요한 역할을 한다. 그러나 최근 연구 The lipschitz constant of self-attention(ICML 2021)에서 standard dot product self-attention 레이어의 립시츠 상수가 무한할 수 있으며, 이는 ViT에서 립시츠 연속성을 위반하게 만든다는 것을 보여준다. ViT discriminator의 Lipschitzness를 강제하기 위해 다음과 같은 L2 attention이 제안되었다.
여기서는 dot product similarity를 Euclidean distance로 대체하고, query와 key의 weights를 tie한다. 이를 통해 Transformer discriminator에 립시츠네스를 강제하고 안정성을 향상시킨다.
Improved Spectral Normalization
립시츠 연속성을 더욱 강화하기 위해 discriminator 훈련에 SN(spectral normalization)도 적용한다. standard SN은 power iteration을 사용해 각 layer의 projection matrix의 spectral norm(=제일 큰 singular value, 최대값)을 추정한다. 그런 다음 weight matrix를 estimated spectral norm으로 나눠 projection matrix의 립시츠 상수가 1이 되도록 한다.
우리는 Transformer block이 립시츠 상수의 스케일에 민감하고, SN을 사용할 때 훈련이 매우 느리게 진행된다는 것을 발견했다. 마찬가지로, ViT-based discriminator를 사용할 때 R1 gradient penalty가 GAN의 훈련을 방해한다는 것을 발견했다.
Attention is not all you need: Pure attention loses rank doubly exponentially with depth는 MLP block의 작은 립시츠 상수가 Transformer의 출력을 rank-1 matrix로 붕괴시킬 수 있음을 보여준다. 이를 해결하기 위해 projection matrix의 spectral norm을 증가시킬 것을 제안한다.
위의 식과 같이 각 레이어의 normalized weight matrix에 spectral norm at initialization을 곱함으로써 이 문제가 해결된다는 것을 발견했다.
Q) 왜 초기화 값의 spectral norm을 곱하지? 그냥 해봤더니 문제가 해결됐다? 흠...
Overlapping Image Patches

ViT discriminator는 learning capacity를 초과하기 때문에 overfitting 되기 쉽다. discriminator와 generator는 미리 정의된 grid P x P에 따라 이미지를 겹치지 않는 patch의 sequence로 분할하는 동일한 이미지 표현을 사용한다. 이러한 임의의 grid partition은 신중하게 조정되지 않을 경우, discriminator가 local 신호를 기억하고 generator에 meaningful loss를 제공하지 못하게 될 수 있다.
이 문제를 해결하기 위해 patch를 o pixel 만큼 확장하여 patch size를 (P + 2o) x (P + 2o)로 겹친다. 이로 인해 sequence의 길이는 동일하게 유지하면서 이전의 미리 정의된 grid에 비해 덜 민감해지고, Transformer는 이웃 patch들간의 정보(어떤 패치가 현재 패치와 인접한 패치인지)를 더 잘 파악해 locality를 더 잘 감지할 수 있게 되기도 한다.
4.2. Generator Design
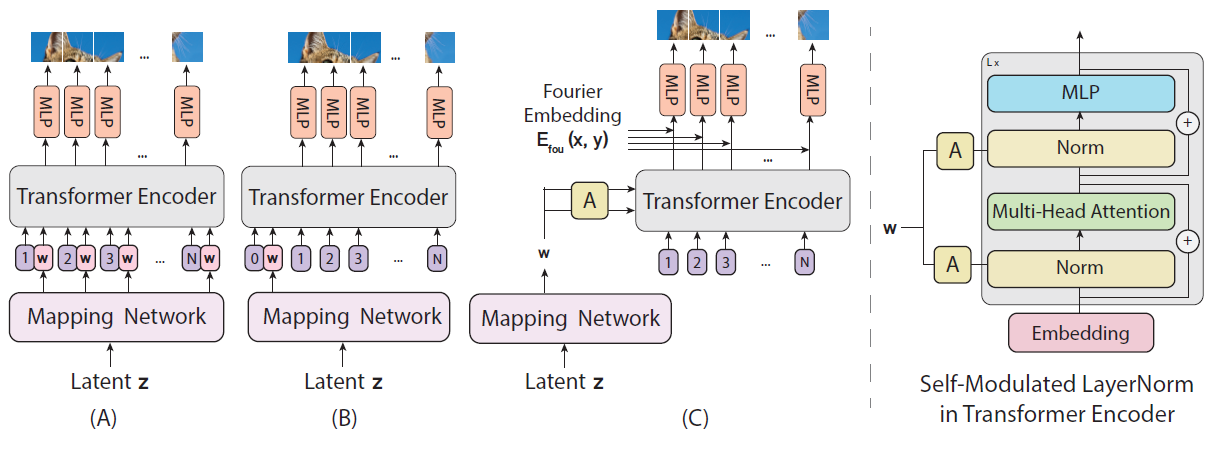
ViT 기반 generator를 설계하기 위해 ViT를 set of class labels을 예측하는 것에서 pixels over a spatial region을 생성하는 것으로 변환해야 한다. 새로운 구조를 설계하기 전에 그럴듯한 base model (A), (B)에 대해 살펴본다. Latent z가 MLP를 거쳐 Latent vector w를 만들고 (A)는 모든 positional embedding에 w를 추가하고 (B)는 앞부분에만 w를 추가했다는 것이 다르다. baseline (A), (B)는 CNN-based generator에 비해 엄청 안좋은 성능을 보였다.
그래서 새로운 generator 구조를 디자인했다.
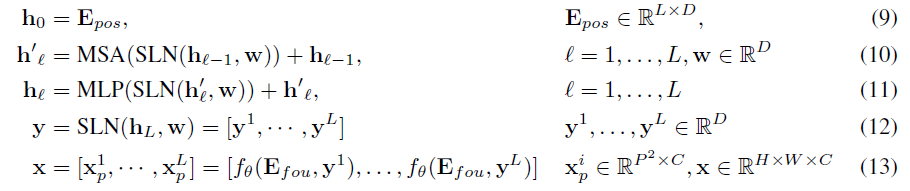
(C)는 Transformer block과 output mapping layer로 구성된다.
Self-modulated LayerNorm
noise vector z를 ViT에 입력으로 보내는 대신, z를 사용하여 layernorm 연산을 한다. modulation이 외부 정보에 의존하지 않기 때문에 self-modulated라고 하고 다음과 같이 계산된다.
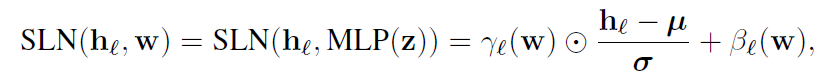
adaptive normalization parameter γ, β는 w로부터 계산하고, μ랑 σ는 layer의 mean, variance를 계산한다.
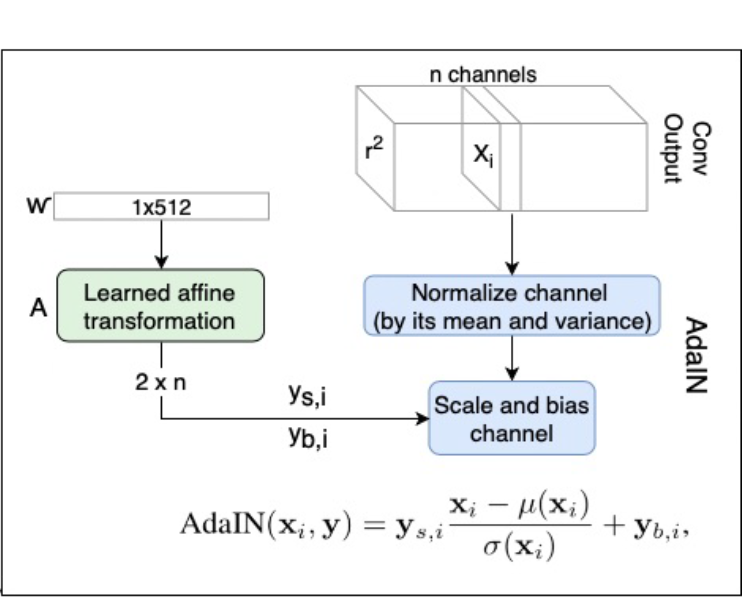
cf) 이는 AdaIN과 함께 보면, normalize channel 대신 normalize layer를 한다는 점만 다르다고 볼 수 있다.
Implicit Neural Representation for Patch Generation
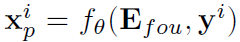
Fourier encoding Efou, 2-layer MLP fθ(‧,‧)
implicit neural representation을 사용하여 patch embedding yi에서 patch pixel value xpi로의 continuous mapping을 학습한다. Fourier feature와 결합할 때 impIicit representation은 생성된 sample 의 공간을 부드럽게 변화하는 자연 신호의 공간으로 제한할 수 있다. implicit representation이 Vit-based generator로 GAN을 훈련하는데 유용하다는 것을 발견했다.
5. Experiments
5.1. Experiment Setup
Dataset
- CIFAR-10: 50K training images and 10K test images
- LSUN bedroom: 3M training images and 300 validation set
- CelebA: 162,700 training images and 19,962 test images
Metric
- IS, FID
비교
- CNN-based: BigGAN, StyleGAN2
- similar model: TransGAN
5.2. Main Results
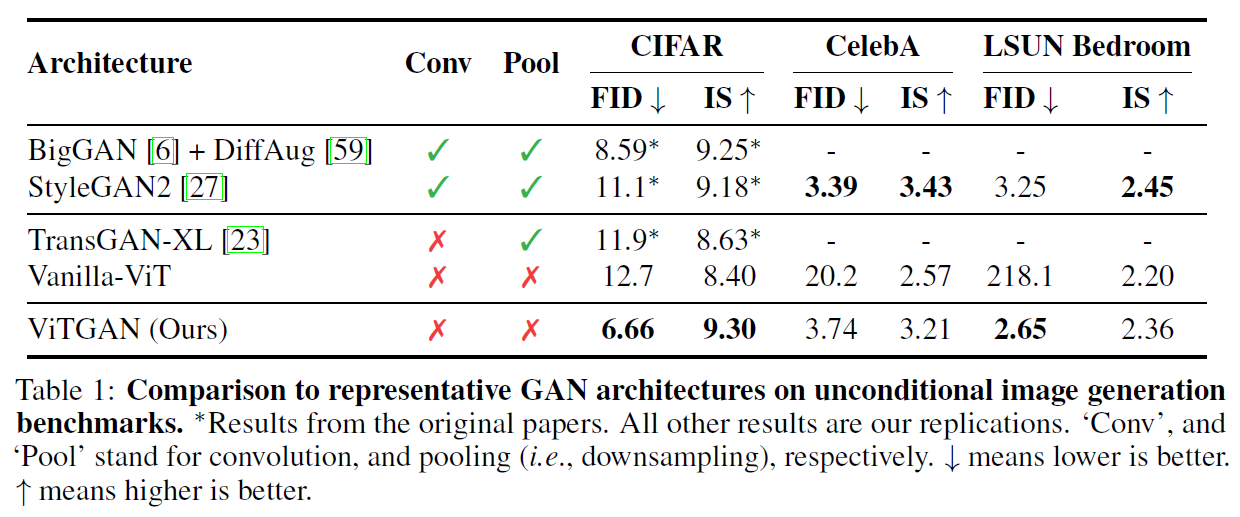
ViTGAN이 Transformer-based GAN에 비해서는 훨씬 좋은 성능을 보였고, Conv, Pool 없이도 CNN-based GAN 모델인 BigGAN, StyleGAN2 만큼 좋은 성능을 보였다.
다음은 생성된 이미지 결과이다.



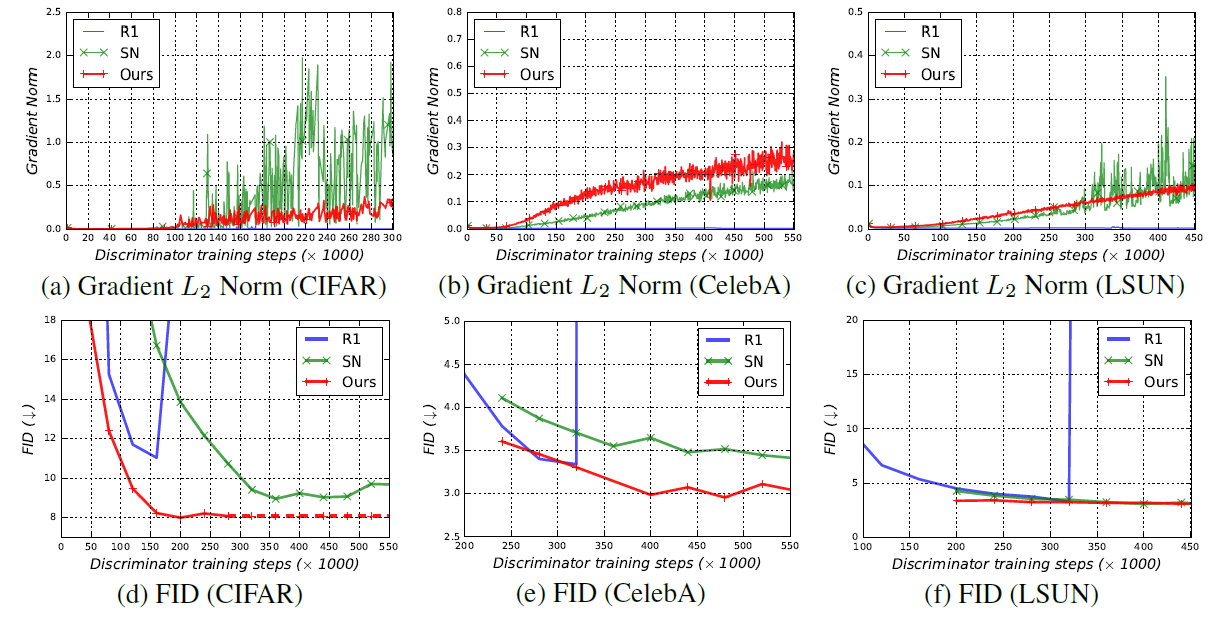
새로 도입한 regularization 방법이 안정적인 학습에 효과를 보인다.
5.3. Ablation studies
Compatibility with CNN-based GAN
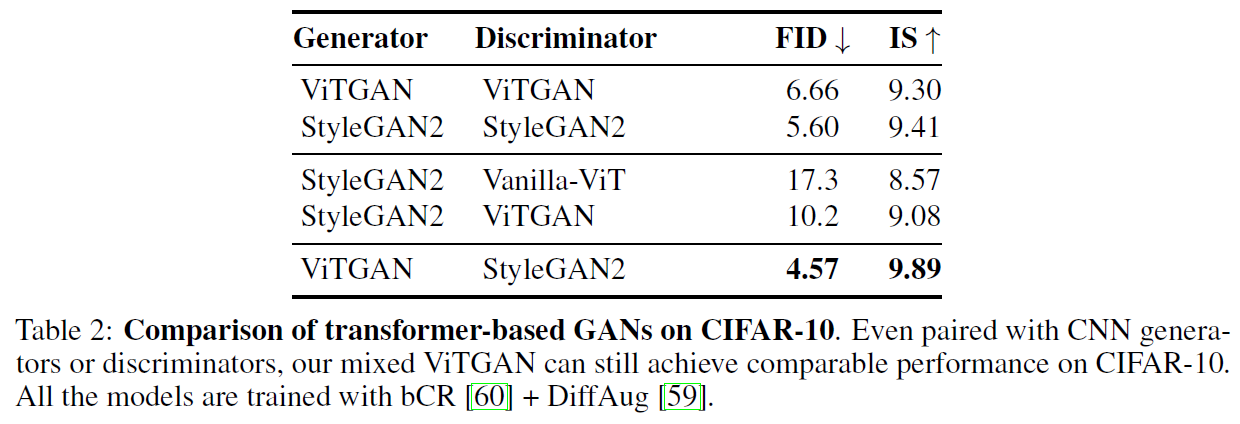
ViTGAN generator와 StyleGAN2 discriminator를 결합했을 때 가장 좋은 결과를 보였다.
Generator architecture and Discriminator regularization
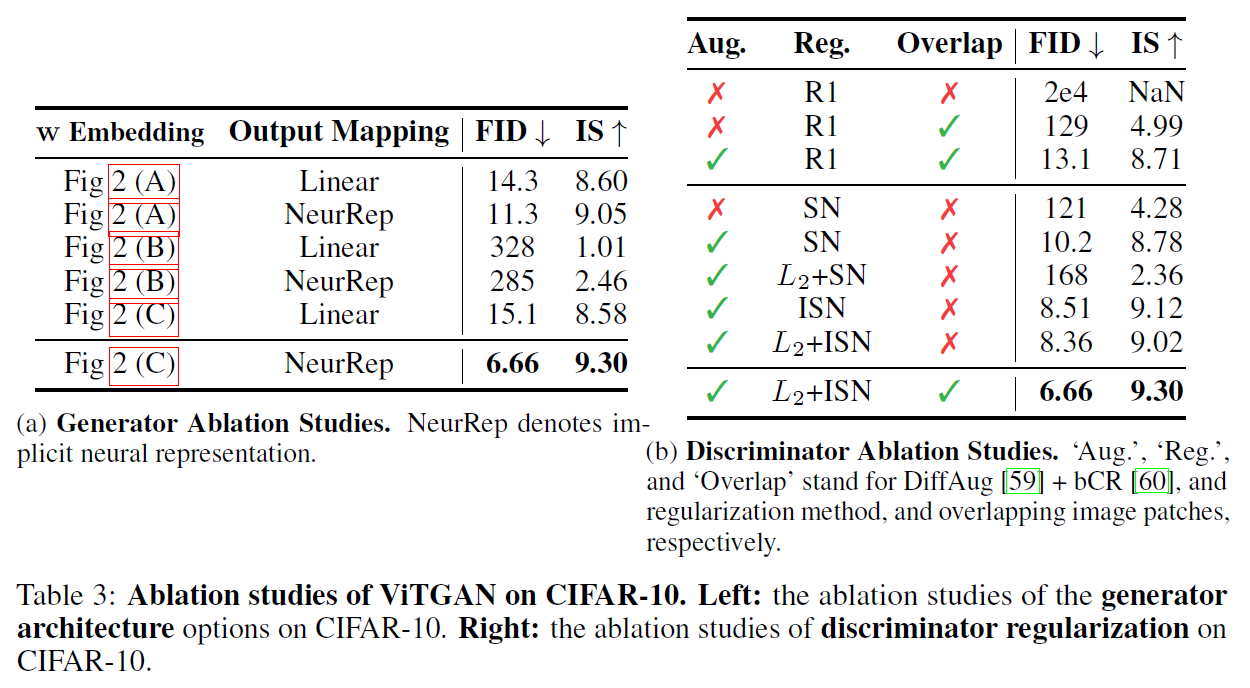
generator에서 w embedding을 사용하는 구조와 implicit neural representation의 효과에 대한 성능을 비교하고 discriminator에서 사용한 reguralization 방법의 효과에 대한 성능을 비교해서 보여준다.
6. Conclusion
ViT를 GAN에 적용한 첫 논문이며, CNN-based GAN과 견줄만한 성능을 보여줬다.
하지만 CNN-based GAN을 완전 뛰어넘지는 못했는데, 오랜시간 연구되어온 CNN-based GAN을 생각하면, 앞으로의 연구를 통해 Transformer-based GAN을 더 발전시킬 수 있는 가능성이 있다.
결과로 생성한 이미지가 32x32, 64x64 로 매우 작아서 더 큰 이미지를 생성하지 못한 이유에 대해 생각해보고 있다.
생성한 이미지의 퀄리티가 떨어져서? 학습이 너무 오래걸려서? patch 단위로 생성하는데 한계가 있었나?
Reference
# 논문
ViTGAN: Training GANs with Vision Transformers
# 영상
[논문 리뷰] ViTGAN: Training GANs with Vision Transformers - 김정예
'Deep Learning > Paper Review' 카테고리의 다른 글
| [Vision/Transformer] MetaFormer is Actually What You Need for Vision (0) | 2022.11.01 |
|---|---|
| [Super Resolution] SwinIR / SwinFIR (0) | 2022.09.19 |