CVPR 2022 Oral 발표 논문으로, 그동안 중요하게 여겨진 Transformer에서 Attention의 역할에 대해 새로운 관점을 제안하는 논문이라 읽어보았다.
1. Introduction & Related work
Transformer는 computer vision의 다양한 task에서 좋은 성능을 보이고 있고, 더 좋은 성능을 위해 개선된 모델들이 계속 연구되고 있다.

Transformer Encoder는 두 개의 컴포넌트로 구성되어 있다.
(1) attention 모듈: token mixer로 토큰 간의 정보를 mixing
(2) channel MLPs, residual connection 같은 나머지 모듈
이 구조에서 attention module을 정해지지 않은 token mixer로 일반화 해 전반적인 Transformer 구조를 표현하는 MetaFormer를 제안한다.
오랫동안, Transformer의 성공 요인은 attention 기반의 token mixer라고 여겨졌다. ("Attention is all you need")
이에 다양한 attention 모듈에 대한 변형이 제안되었다.
e.g., T2T-ViT, PVT, DeiT and Swin
(focusing on improving the token mixing approach of Transformers)
하지만, 최근에는 attention 모듈을 spatial MLPs로 대체한 모델이 제안되었고, 경쟁력있는 성능을 보이고 있다.
e.g., MLP-Mixer
후속 연구들은 data-efficient training, 특정 MLP 모듈 설계를 통해 MLP-like 모델을 발전시키고 있고, ViT와의 성능 격차를 좁히며 attention 기반 token mixer의 우위에 도전하고 있다.
최근 몇몇 다른 연구들은 MetaFormer 구조에서 또 다른 유형의 token mixer(FNet의 Fourier Transform)를 탐색하기도 했다.
모든 결과를 종합해, 이 논문에서는 Transformer 모델 성능의 결정적인 요인은 attention과 같은 특정한 token mixer가 아니라, 일반화된 구조인 MetaFormer라는 가설을 세웠다.
이 가설을 검증하기 위해서 token mixer로 아주 단순한 non-parametic operator인 pooling을 적용해봤다. 놀랍게도, PoolFormer는 경쟁력있는 성능을 달성하며, Transformer 기반의 DeiT, MLP-like 모델인 ResMLP의 성능을 능가했다. (이 이야기가 token mixer가 중요하지 않다는 이야기는 아니며, 다만 어떤 특정한 token-mixer가 중요한 게 아니라는 의미다.)
+) MACs가 뭐지...?
딥러닝에서 파라미터 개수와 함께, 계산량을 통해 모델이 얼마나 큰지, 효율적인지 나타내는 지표가 있다.
계산량은 보통 FLOPs(FLoating point OPerations) 혹은 MAC(Multiply-ACcumulate)으로 나타낸다.
1 MACs = 2 FLOPs (MACs은 a*x+b를 하나의 연산으로, FLOPs는 덧셈, 곱셈을 각각의 연산으로...?)
(https://bongjasee.tistory.com/3)
이 논문의 목적은 sota를 달성하기 위한 새롭고 복잡한 token mixer를 설계하는 것이 아니다.
대신, "What is truly responsible for the success of the Transformers and their variants?" 라는 Transformer의 성공 요인에 대한 근본적인 질문을 던진다.
그 대답은 일반화된 구조 MetaFormer이고, PoolFormer로써 이를 증명했다.
한편, 동일한 질문에 대답하는 몇몇 논문들이 있다.
"Attention is not all you need: pure attention losses rank doubly exponentially with depth"
- Attention 이외에도 skip connection(residual connection), MLP 중요하다.
- 그게 없이 Multi-head Attention만 사용한 네트워크를 만들면 layer가 많아질수록 output matrix가 query에 상관없이 모든 row가 동일해지는 rank-1 matrix로 수렴하게 된다는 것을 입증했다.
"Do vision transformers see like convolutional neural networks?"
- ViT와 CNN의 특징 차이를 비교한다.
- self-attention은 global 정보를 조기에 모을 수 있도록 하고, residual connection은 feature를 하위 계층에서 상위 계층으로 강력하게 전파한다.
"How do vision transformers work?"
- multi-head self-attentions의 accuracy, generalization 향상은 loss landscape의 flattening을 통한 것이다.
하지만, 위 논문들은 Transformer를 일반적인 구조로 추상화하지 않았고, 일반 프레임워크 측면에서 연구한다.(?)
2. Method
2.1. MetaFormer
MetaFormer는 token mixer가 정해지지 않은 일반적인 구조이고, 다른 요소들은 Transformer와 동일하다.
input I는 처음으로 Input embedding(e.g., ViT의 patch embedding)을 거친다.
그리고 embedding token들은 반복적인 MetaFormer block으로 입력된다.
각 MetaFormer block은 두 개의 residual sub-block을 포함한다.
첫 번째 sub-block은 토큰 간의 정보를 전달하는 token mixer를 포함한다.
여기서 Norm은 normalization(e.g., Layer Normalization, Batch Normalization),
TokenMixer는 다양한 vision Transformer 모델의 attention mechanism이나 MLP-like 모델의 spatial MLP를 의미한다.
+) token mixer는 token 정보들을 전파하는데 attention과 같은 몇몇 token mixer들은 channel도 mix한다.
MLP-Mixer에서 token-mixing MLP, channel-mixing MLP와 연결지어 생각해봐야겠다.
두 번째 sub-block은 two-layered MLP + non-linear activation으로 구성된다.
여기서 MLP expansion ratio r은 feature map을 한 번 확장했다가 줄이는 역할을 한다.
+ activation function(e.g., GELU, ReLU)
이러한 MetaFormer는 token mixer를 지정함에 따라 Transformer(Attention), MLP-like model(Spatial MLP)이 될 수 있다.
2.2. PoolFormer
MetaFormer의 일반적인 구조가 최근 Transformer 및 MLP-like 모델의 성공 요인이라고 주장하고,
이를 입증하기 위해 일부러 pooling이라는 간단한 연산자를 token mixer로 사용했다.
pooling은 학습 가능한 파라미터가 없으며, 그저 각 토큰이 인접한 토큰 피쳐들을 평균적으로 집계한다.
Pooling Token Mixer
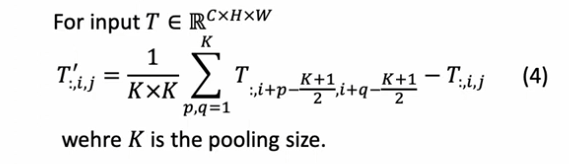
여기서 MetaFormer block은 이미 residual connection을 가지고 있기 때문에 입력을 빼준다.
PoolFormer Framework
self-attention과 spatial MLP는 mix token 수에 대한 계산 복잡도가 제곱이다. 여기에 spatial MLP는 긴 시퀀스를 처리할 때 훨씬 더 많은 파라미터를 갖는다. 이로 인해 self-attention과 spatial MLP는 보통 수백개의 토큰만 처리 가능하다.
반면, pooling은 시퀀스 길이에 linear한 계산 복잡도를 갖고, 학습 가능한 파라미터가 없다. 따라서 기존의 CNN(e.g., AlexNet, VGG, ResNet) 및 최근의 계층적 Transformer 변형(e.g., Swin-T, PVT)과 유사한 계층(hierarchical) 구조를 채택함으로써 pooling의 이점을 활용한다.
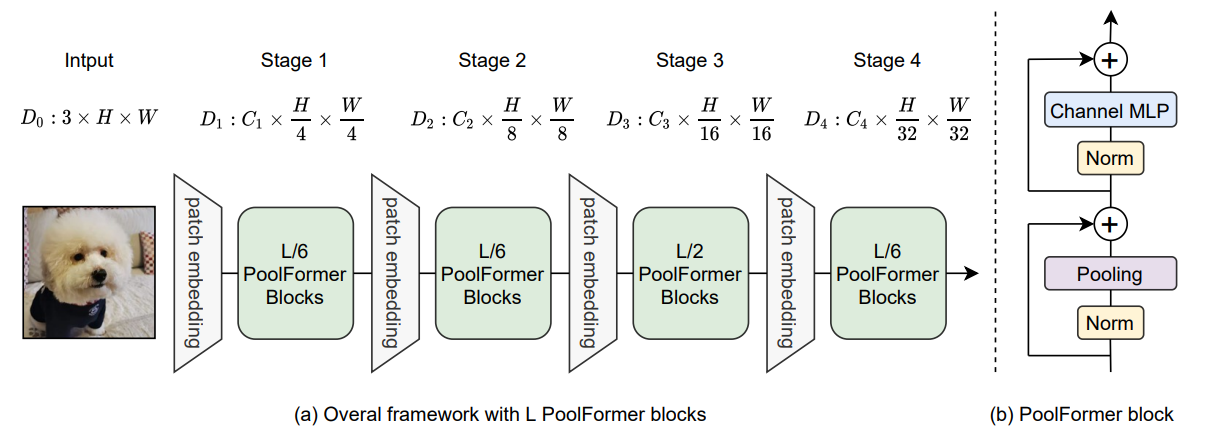
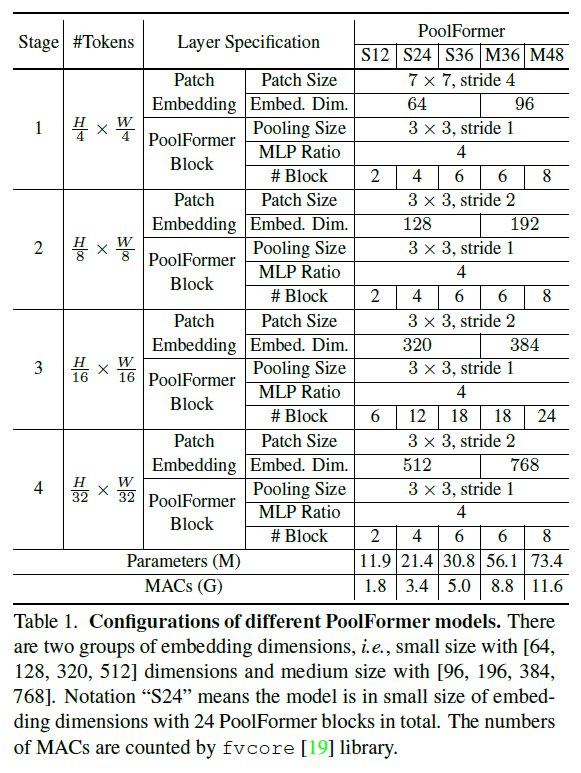
PoolFormer는 토큰의 4개의 stage(4, 8, 16, 32)가 있고,
임베딩 크기에 따라 두 개의 그룹이 있다.
1) small-sized models: 64, 128, 320, 512
2) medium-sized models: 96, 192, 384, 768
총 L개의 PoolFormer 블록이 있다면, stage에 따라 L/6, L/6, L/2, L/6개의 블록이 포함되고,
MLP expansion 비율은 4로 설정했다.
이런 규칙에 따라 논문에서는 아래와 같이 5개의 서로 다른 모델을 구성했다.
3. Experiments
computer vision의 다양한 task에서 좋은 성능을 보였음을 알 수 있다. (논문 참고)
3.1. Image classification
3.2. Object detection and instance segmentation
3.3. Semantic segmentation
3.4. Ablation studies
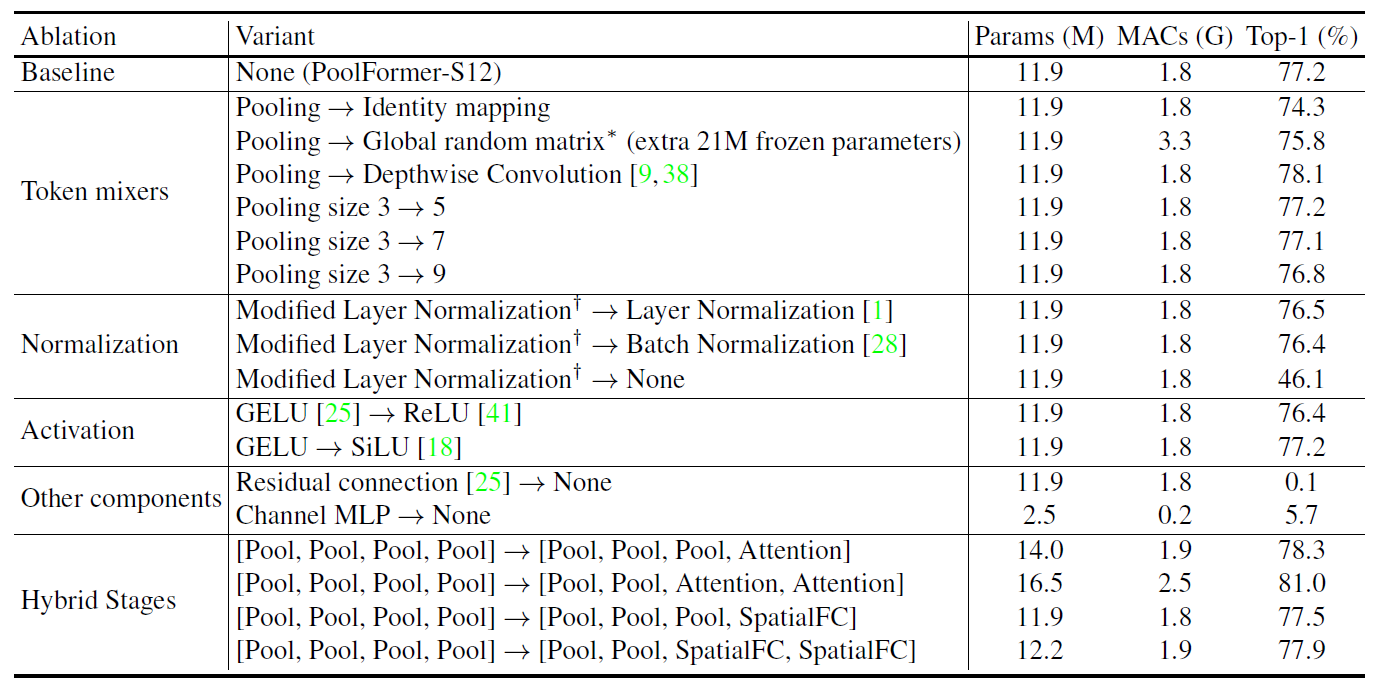
Token mixers
Pooling을 Indentity mpping으로 바꾸어 input을 똑같이 뒤로 넘겨주었을 때도 성능이 74.3%가 나왔다.
Pooling을 random token mixing인 global random matrix(random initialization)와 learnable parameter가 있는 depthwise convolution으로 바꿨을 때 조금의 성능 향상이 있었다. 놀랍지 않게 token mixer에 따라 보장된 성능을 보여줬는데 이 논문의 핵심인 MetaFormer 구조를 보여주기 위해 단순한 pooling을 사용했다.
Pooling size의 경우 3, 5, 7, 9로 늘려봤지만 오히려 성능이 떨어져 3을 default로 했다.
Normalization
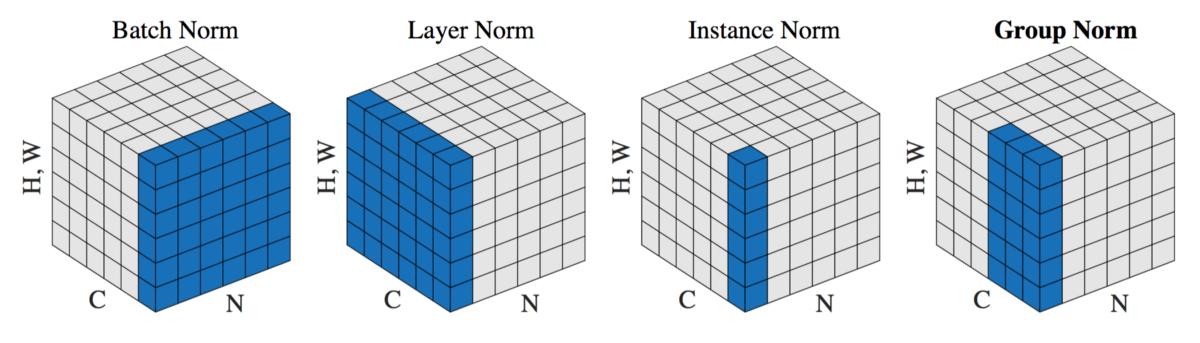
여기서는 Modified Layer Normalization(MLN) (= patch-wise Group Norm)을 사용했다.
mean, variance를 오직 channel dimension에 대해 계산하는 vanilla Layer Norm과 달리 token, channel dimension에 대해 계산한다.
Normalization을 아예 없애자 성능이 큰 폭으로 46.1%까지 떨어졌다.
Activation
크게 영향을 주지 않는다.
Other Components
Residual connection, Channel MLP는 아주 중요하다. 없애면 아예 성능이 안나오는 수준이다.
Hybrid Stages
4개의 pooling stage에 attention, spatial MLP를 넣어서 hybrid 성능이 더 잘나오는지 탐색해봤다.
pooling은 더 긴 입력 시퀀스를 처리할 수 있고, attention과 spatial MLP는 global information을 잘 얻기 때문에 pooling을 bottom stage에 attention과 spatial MLP를 top stage에 배치했다.(top stage에서 시퀀스가 크게 단축되었기 때문에)
성능이 꽤 많이 올라가는 효과를 얻을 수 있었다.
MetaFormer에 pooling만 사용하는 것보다 다른 token mixer와 결합했을 때 성능을 더욱 향상시킬 수 있다.
4. Conclusion and future work
이 논문에서는 Transformer의 attention을 token mixer로 추상화하고, token mixer가 정해지지 않은 MetaFormer라는 일반화된 구조로 전체 Transformer를 추상화했다. 특정 token mixer에 초점을 맞추는 대신, MetaFormer가 성능을 위해 실제로 우리가 필요한 것이라고 주장한다. 이를 검증하기 위해 의도적으로 매우 단순한 pooling을 token mixer로 사용했는데, PoolFormer는 다양한 비전 task에서 경쟁력있는 성능을 달성했으며, "MetaFormer is actually what you need for vision"이라는 말을 잘 뒷받침한다.
향후, self-supervised learning, transfer learning과 같은 더 다양한 learning setting에 대해 추가로 평가할 예정이다. 또한, "MetaFormer is actually what you need"라는 말을 뒷받침 하도록 MetaFormer가 NLP task에서도 유의미한지 확인하는 것도 흥미롭다. 앞으로의 연구가 token mixer 모듈에만 집중하기보다, 기본 구조인 MetaFormer를 개선하는데 집중하는 영감을 줄 수 있기를 바란다.
그렇다면 Attention과 상관없이 MetaFormer 구조 자체가 잘 작동하는 이유는 무엇일까...?
Reference
# 논문
MetaFormer Is Actually What You Need for Vision
# 영상
MetaFormer Is Actually What You Need for Vision | CVPR 2022
딥러닝논문읽기모임 [2022 CVPR] MetaFormer is Actually What You Need for Vision 논문 리뷰
# 블로그
'Deep Learning > Paper Review' 카테고리의 다른 글
| [GAN] ViTGAN: Training GANs with Vision Transformers (0) | 2022.12.22 |
|---|---|
| [Super Resolution] SwinIR / SwinFIR (0) | 2022.09.19 |